Update (Mar 4, 2026): A follow-up with
vajra-search v0.2.1build improvements and refreshed ZVec corpus-scale benchmarks is here: Vajra Search v0.2.1 update.
This post documents the technical continuity from:
- Vajra lexical benchmarking work (BM25 engine comparisons),
- Vajra vector search v0.4.1 and v0.5.0 in Python,
- Rust-backed
vajra_searchHNSW with PyO3 bindings.
It focuses on engineering decisions and measured behavior, not language advocacy.
A detailed preprint version of this work is being prepared for arXiv submission.
The intended audience is engineers who care about retrieval systems in production: index build windows, latency envelopes, recall stability, and integration constraints.
1) Continuity: BM25 -> vector search -> Rust backend

2) Prior benchmark context (before vector v0.4.1)
Before the vector-search re-engineering, Vajra was benchmarked as a BM25 engine against multiple systems. The original technical report is here:
That report includes comparisons against:
bm25sbm25s-paralleltantivypyserinivajra-parallel
A compact snapshot from that phase:
| Dataset family | Engines compared | Main takeaway |
|---|---|---|
| BEIR (SciFact, NFCorpus) | Vajra, BM25S, Tantivy, Pyserini | Pyserini often led accuracy; Vajra emphasized latency/QPS |
| Wikipedia 200k/500k | Vajra, BM25S, Tantivy, Pyserini | Distinct build/latency/accuracy trade-offs across engines |
This prior work matters because it established a benchmarking discipline used again for vector search: explicit baselines, fixed query protocol, and metric-level reporting.
That continuity matters because the Rust work should not be interpreted as a fresh benchmark starting point. It is a continuation of the same measurement practice and the same operational questions from the BM25 phase: what do we gain, what do we lose, and what trade-offs can be controlled explicitly.
3) ZVec as the trigger for v0.5.0 re-engineering
The initial Feb 22 baseline established the v0.4.1 gap against ZVec at 10k vectors.
That same post contains the full v0.5.0 optimization walkthrough (six implementation fixes), which is the canonical source for the Python-side gains before Rust.
3.1 Baseline (v0.4.1)
| Metric | ZVec | Vajra v0.4.1 |
|---|---|---|
| Build time | 0.47 s | 97.77 s |
| p50 query | 0.31 ms | 2.63 ms |
| Recall@10 | 1.000 | 0.987 |
3.2 Gains in v0.5.0 (from the separate profiling post)
| Metric | ZVec | Vajra v0.4.1 | Vajra v0.5.0 | v0.4.1 -> v0.5.0 gain |
|---|---|---|---|---|
| Build time | 0.47 s | 97.77 s | 17.03 s | 5.7x faster |
| p50 query | 0.31 ms | 2.63 ms | 0.51 ms | 5.2x faster |
| p95 query | 0.42 ms | 3.77 ms | 0.71 ms | 5.3x faster |
| p99 query | 0.53 ms | 4.30 ms | 0.86 ms | 5.0x faster |
| QPS | 3,058 | 374 | 1,911 | 5.1x higher |
| Recall@10 | 1.000 | 0.987 | 0.997 | +1.0% |
Net effect from that stage:
- Build gap to ZVec reduced from roughly 207x to about 36x.
- Query gap to ZVec reduced from roughly 8.5x to about 1.6x.
At this stage, the engineering question changed from "can Python be optimized?" to "which remaining costs are structural and should move to a systems layer?"
4) Why move to Rust after v0.5.0
After v0.5.0, two constraints remained:
- per-step interpreter overhead in HNSW hot loops,
- mutable graph updates under heavy insertion/search workloads.
Rust was used to address those constraints while keeping the Python interface stable.
The design goal was not to replace the Python developer surface. The goal was to preserve the same API ergonomics while moving the high-frequency ANN primitives (graph traversal, candidate-heap mutation, distance dispatch) into a lower-overhead execution layer.
4.1 Architectural motivations
- Predictable memory behavior: contiguous vector storage and explicit layered adjacency reduce pointer-chasing variance in traversal-heavy loops.
- Lower hot-path overhead: candidate-heap updates and distance dispatch run in compiled code rather than Python-level dispatch.
- Safer mutation semantics: Rust ownership/borrowing constraints make graph-update paths easier to reason about under heavy insert/search cycles.
- Throughput headroom: batch query paths can use native parallel execution (Rayon) without changing the Python API.
- No API break for users: PyO3 keeps the Python entry points stable while delegating execution to Rust.
4.2 Python-Rust integration map

4.3 Custom HNSW implementation notes
The Rust HNSW implementation in crates/vajra-hnsw is not a wrapper around an external ANN library. It is implemented directly for this stack, including:
- graph storage (
Vec<f32>vectors + layered adjacency), - upper-layer greedy descent,
- layer-0 beam search (
beam_search_fast), - profile parameter surface (
M,ef_construction,ef_search,use_heuristic), - explicit coalgebra reference path for parity and verification.
In practice, this means benchmark deltas can be attributed to Vajra's implementation choices instead of hidden behavior in a third-party ANN binding.
5) Critical path differences: quality vs fast vs instant
Profiles are not just parameter presets; they change traversal work in both build and query paths.
M and ef_construction primarily shape insertion/build work (graph connectivity and candidate exploration), while ef_search shapes query-time frontier size. Disabling heuristics changes neighbor-selection cost and can materially reduce CPU work at some recall cost.
| Profile | Build critical path | Query critical path | 50k result |
|---|---|---|---|
quality |
higher connectivity + wider exploration during insertion | larger candidate/result frontier for higher recall | 81.343s build, 0.235ms p50, Recall@10 0.998 |
fast |
same M/construction beam as quality, but less expensive neighbor heuristics |
reduced per-step overhead with moderate frontier quality | 28.512s build, 0.184ms p50, Recall@10 0.948 |
instant |
smaller graph degree and smaller beams reduce insertion work aggressively | smallest frontier, lowest traversal cost | 6.777s build, 0.113ms p50, Recall@10 0.706 |
A practical operating pattern follows:
- boot with
instantfor low startup latency, - rebuild asynchronously with
quality, - atomically swap index handles when quality build completes.
This pattern should be read as an explicit control-plane design: startup latency and final recall are treated as separate objectives with a deterministic handoff.
5.1 Formalization: Profile-Lambda Retrieval Architecture (PLRA)
The deployment pattern above is structurally similar to Lambda Architecture in data engineering (Databricks glossary), but adapted for ANN index lifecycle rather than stream/batch ETL.
I refer to this as Profile-Lambda Retrieval Architecture (PLRA):
- Serving/Instant path: minimal-connectivity index for immediate availability.
- Speed/Fast path: moderate-cost index for better steady latency/recall while rebuilds continue.
- Batch/Quality path: high-recall full build in the background.
- Reconciliation: atomic index-handle swap when quality build is ready.

This gives a reproducible control surface: startup SLOs are decoupled from final ranking quality, and quality can be converged asynchronously.
Conceptually, PLRA is useful because it turns a tuning trade-off into an architecture primitive: profile transitions become part of deployment policy rather than ad-hoc runtime tweaking.
6) Current Rust benchmark snapshot (Wikipedia vectors)
Benchmarks were run for 1k, 10k, 20k, and 50k vectors.
6.1 Build/recall at 50k
| Engine/Profile | Build (s) | Recall@10 |
|---|---|---|
| ZVec | 2.481 | 1.000 |
| Vajra quality | 81.343 | 0.998 |
| Vajra fast | 28.512 | 0.948 |
| Vajra instant | 6.777 | 0.706 |
6.2 Query at 50k
| Engine/Profile | p50 (ms) | QPS |
|---|---|---|
| ZVec | 0.774 | 1305.2 |
| Vajra quality | 0.235 | 4241.8 |
| Vajra fast | 0.184 | 5325.9 |
| Vajra instant | 0.113 | 8624.7 |
6.3 Figures
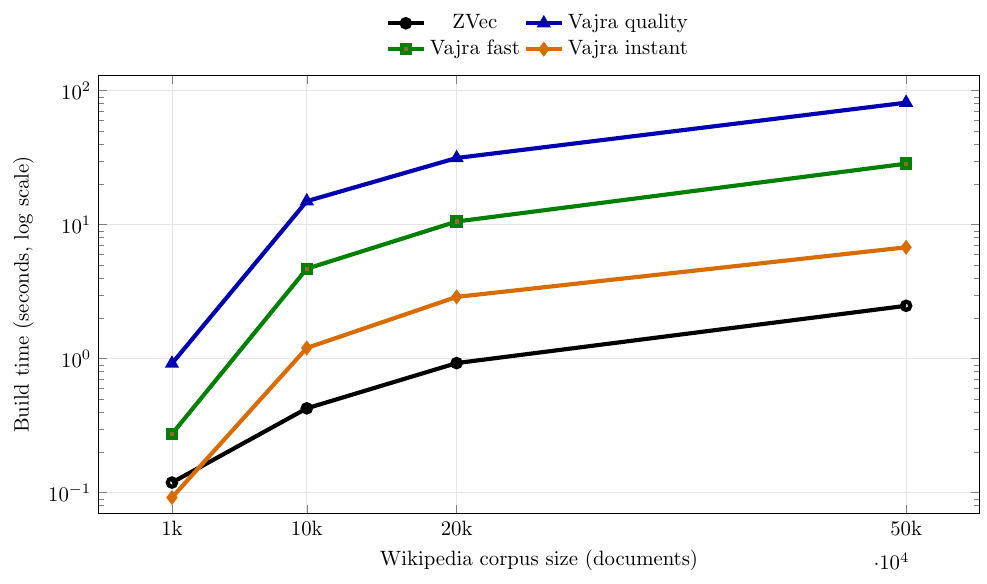
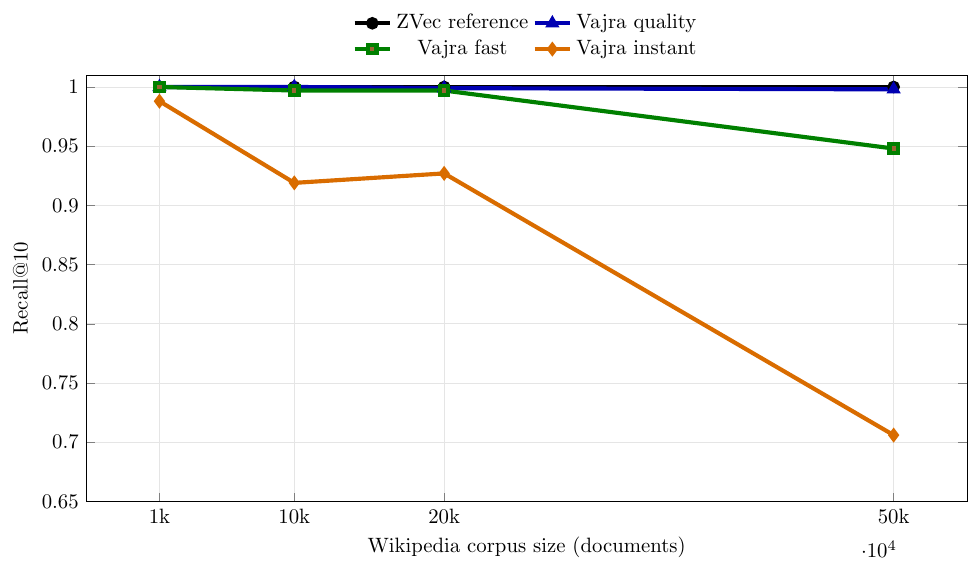
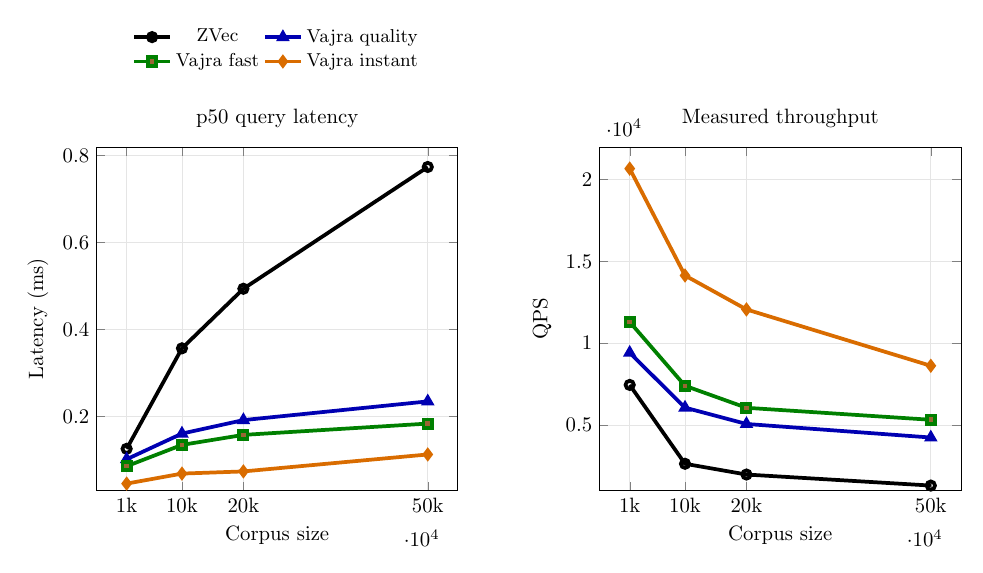
Reading these plots together:
- Build time separates profiles the most as corpus size grows.
- Query latency stays low for all Vajra profiles in this setup.
- Recall degradation is concentrated in
instant, whilequalityremains close to the reference. fastacts as a middle operating point for teams that need lower build cost without dropping toinstantrecall.
7) Reproduction notes (Wikipedia data source)
The benchmark corpus slices are sourced from ir_benchmark_data, which is built from Wikipedia-focused IR corpora used in prior Vajra benchmarking.
At a high level:
- Acquire documents from WikIR corpora through
ir_datasets(for examplewikir/en78k, with smaller fallback sets). - Normalize into JSONL snapshots with stable fields (
id,title,content,metadata). - Generate embeddings (
all-MiniLM-L6-v2, 384d) and keep the same embedding cache across engine/profile runs. -
Slice consistently into 1k/10k/20k/50k subsets for direct comparisons.
-
Data location used locally:
~/Github/ir_benchmark_data - Benchmark harness location:
~/Github/zvec_vajra_benchmark
Detailed reproducibility instructions (including expected directory wiring and commands) are provided in: